 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerforming Nonlinear Blind Source Separation with Signal Invariants
Apr 03, 2009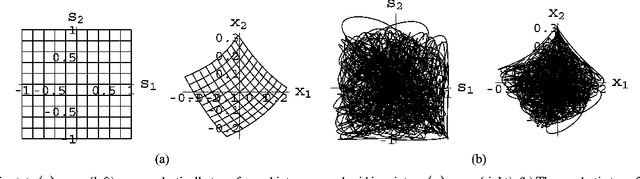
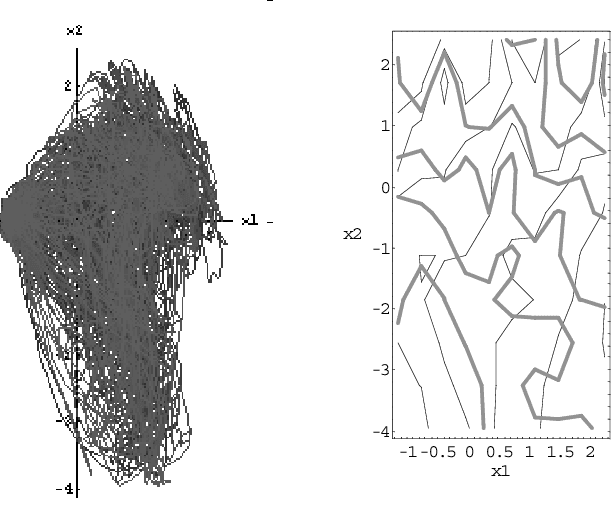
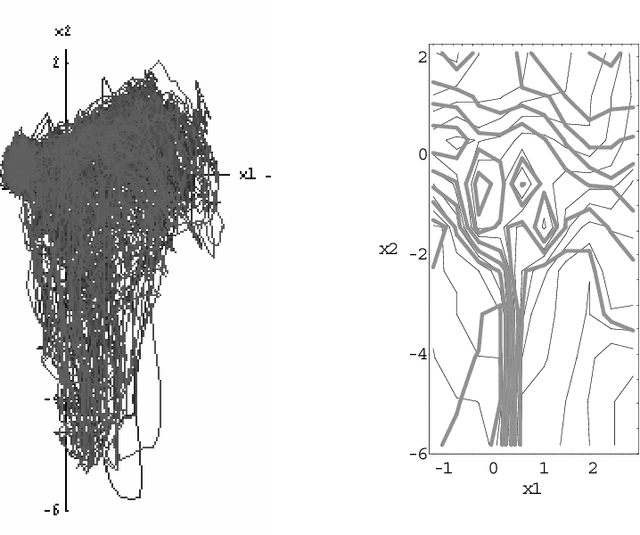
Given a time series of multicomponent measurements x(t), the usual objective of nonlinear blind source separation (BSS) is to find a "source" time series s(t), comprised of statistically independent combinations of the measured components. In this paper, the source time series is required to have a density function in (s,ds/dt)-space that is equal to the product of density functions of individual components. This formulation of the BSS problem has a solution that is unique, up to permutations and component-wise transformations. Separability is shown to impose constraints on certain locally invariant (scalar) functions of x, which are derived from local higher-order correlations of the data's velocity dx/dt. The data are separable if and only if they satisfy these constraints, and, if the constraints are satisfied, the sources can be explicitly constructed from the data. The method is illustrated by using it to separate two speech-like sounds recorded with a single microphone.
Using state space differential geometry for nonlinear blind source separation
Dec 19, 2006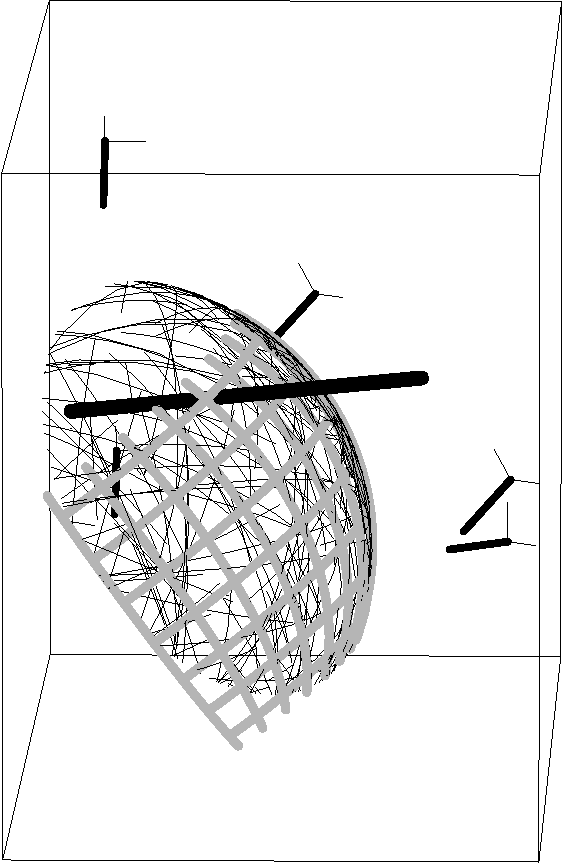
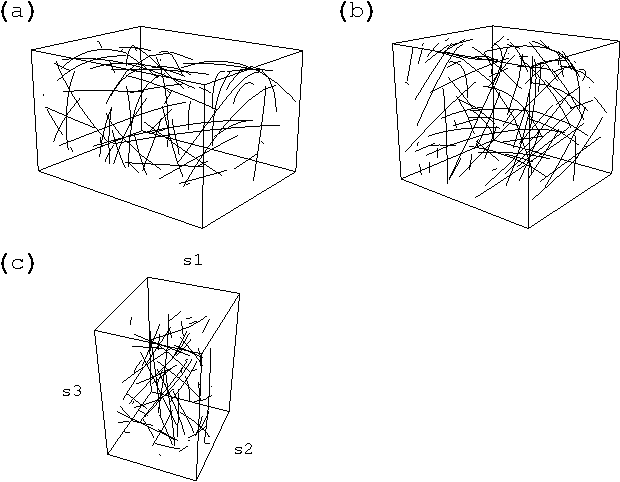
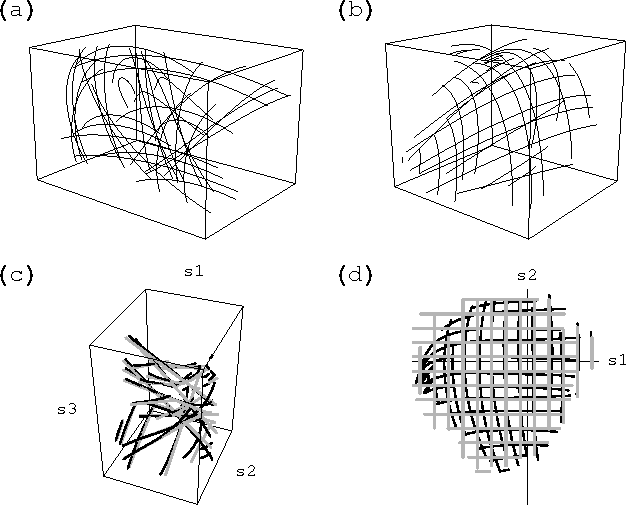
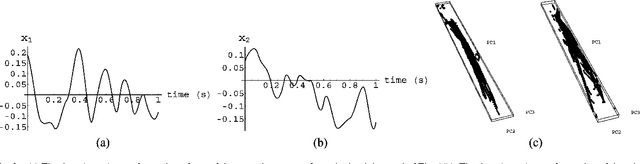
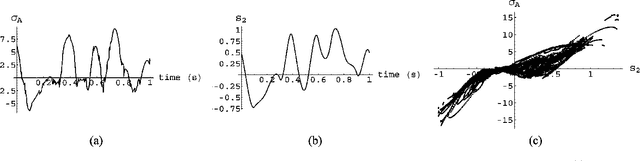
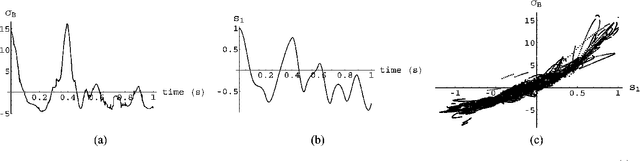
Given a time series of multicomponent measurements of an evolving stimulus, nonlinear blind source separation (BSS) seeks to find a "source" time series, comprised of statistically independent combinations of the measured components. In this paper, we seek a source time series with local velocity cross correlations that vanish everywhere in stimulus state space. However, in an earlier paper the local velocity correlation matrix was shown to constitute a metric on state space. Therefore, nonlinear BSS maps onto a problem of differential geometry: given the metric observed in the measurement coordinate system, find another coordinate system in which the metric is diagonal everywhere. We show how to determine if the observed data are separable in this way, and, if they are, we show how to construct the required transformation to the source coordinate system, which is essentially unique except for an unknown rotation that can be found by applying the methods of linear BSS. Thus, the proposed technique solves nonlinear BSS in many situations or, at least, reduces it to linear BSS, without the use of probabilistic, parametric, or iterative procedures. This paper also describes a generalization of this methodology that performs nonlinear independent subspace separation. In every case, the resulting decomposition of the observed data is an intrinsic property of the stimulus' evolution in the sense that it does not depend on the way the observer chooses to view it (e.g., the choice of the observing machine's sensors). In other words, the decomposition is a property of the evolution of the "real" stimulus that is "out there" broadcasting energy to the observer. The technique is illustrated with analytic and numerical examples.
* Contains 14 pages and 3 figures. For related papers, see http://www.geocities.com/dlevin2001/ . New version is identical to original version except for URL in the byline
Channel-Independent and Sensor-Independent Stimulus Representations
Sep 26, 2005
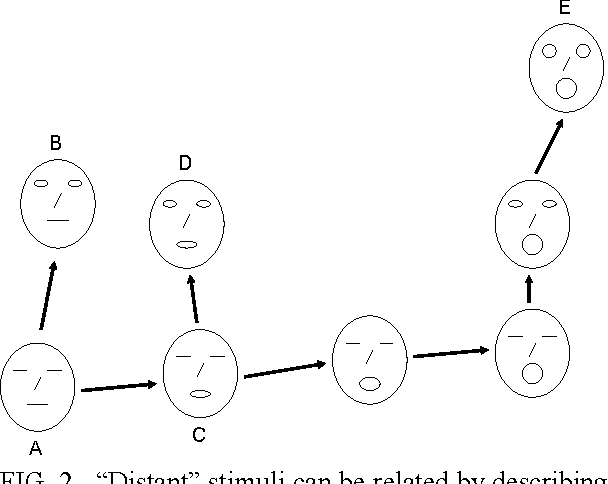
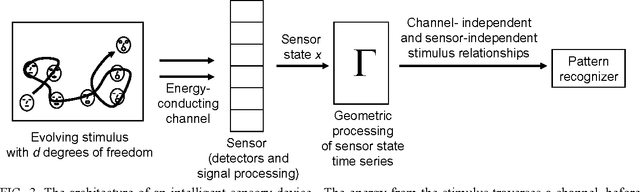
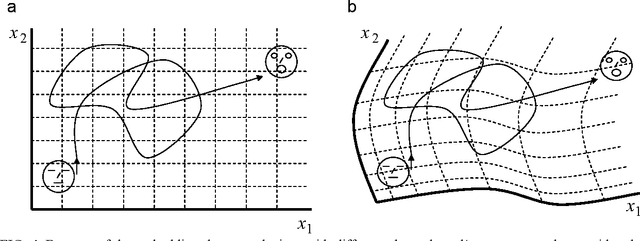
This paper shows how a machine, which observes stimuli through an uncharacterized, uncalibrated channel and sensor, can glean machine-independent information (i.e., channel- and sensor-independent information) about the stimuli. First, we demonstrate that a machine defines a specific coordinate system on the stimulus state space, with the nature of that coordinate system depending on the device's channel and sensor. Thus, machines with different channels and sensors "see" the same stimulus trajectory through state space, but in different machine-specific coordinate systems. For a large variety of physical stimuli, statistical properties of that trajectory endow the stimulus configuration space with differential geometric structure (a metric and parallel transfer procedure), which can then be used to represent relative stimulus configurations in a coordinate-system-independent manner (and, therefore, in a channel- and sensor-independent manner). The resulting description is an "inner" property of the stimulus time series in the sense that it does not depend on extrinsic factors like the observer's choice of a coordinate system in which the stimulus is viewed (i.e., the observer's choice of channel and sensor). This methodology is illustrated with analytic examples and with a numerically simulated experiment. In an intelligent sensory device, this kind of representation "engine" could function as a "front-end" that passes channel/sensor-independent stimulus representations to a pattern recognition module. After a pattern recognizer has been trained in one of these devices, it could be used without change in other devices having different channels and sensors.
Blind Normalization of Speech From Different Channels
Apr 10, 2003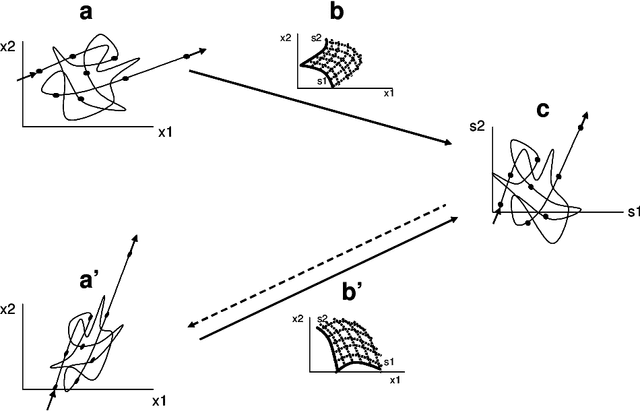
We show how to construct a channel-independent representation of speech that has propagated through a noisy reverberant channel. This is done by blindly rescaling the cepstral time series by a non-linear function, with the form of this scale function being determined by previously encountered cepstra from that channel. The rescaled form of the time series is an invariant property of it in the following sense: it is unaffected if the time series is transformed by any time-independent invertible distortion. Because a linear channel with stationary noise and impulse response transforms cepstra in this way, the new technique can be used to remove the channel dependence of a cepstral time series. In experiments, the method achieved greater channel-independence than cepstral mean normalization, and it was comparable to the combination of cepstral mean normalization and spectral subtraction, despite the fact that no measurements of channel noise or reverberations were required (unlike spectral subtraction).
Blind Normalization of Speech From Different Channels and Speakers
Apr 02, 2002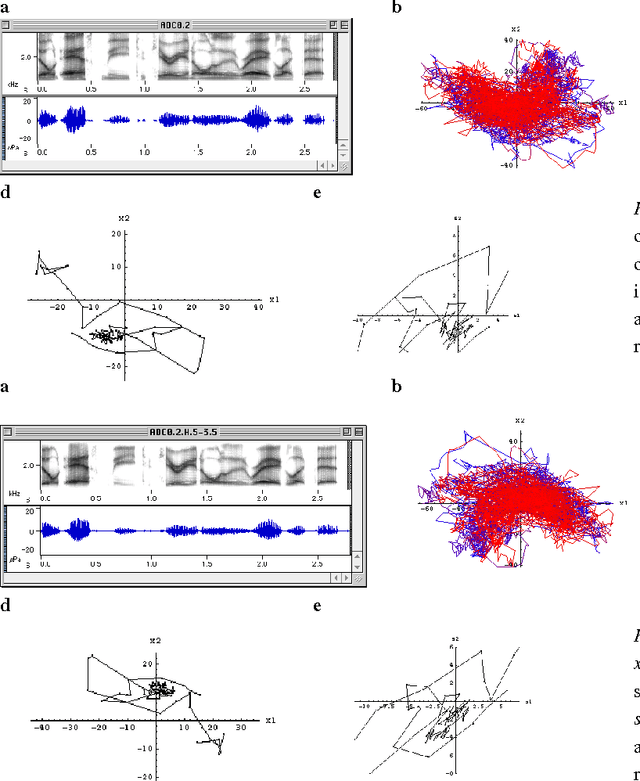
This paper describes representations of time-dependent signals that are invariant under any invertible time-independent transformation of the signal time series. Such a representation is created by rescaling the signal in a non-linear dynamic manner that is determined by recently encountered signal levels. This technique may make it possible to normalize signals that are related by channel-dependent and speaker-dependent transformations, without having to characterize the form of the signal transformations, which remain unknown. The technique is illustrated by applying it to the time-dependent spectra of speech that has been filtered to simulate the effects of different channels. The experimental results show that the rescaled speech representations are largely normalized (i.e., channel-independent), despite the channel-dependence of the raw (unrescaled) speech.